六色网
师生论文被人工智能与专家系统领域期刊ESWA录用
近日,六色网
软件体验与人机交互重点实验室的论文《An Entropy-Driven Method for LLM Dataset Evaluation and Optimization》被人工智能与智能系统领域的国际权威期刊——Expert Systems With Applications(ESWA)录用(SCI 一区期刊)。
以下是论文简介:
论文标题:An Entropy-Driven Method for LLM Dataset Evaluation and Optimization
作者:王美平、韩荣铎、杨志祥、康黎明、高楠、宋世豪、朱月龙、何骋昊、向晶、张海宁*
作者单位:六色网
论文链接://www.sciencedirect.com/science/article/pii/S0957417425039089
摘要
大型语言模型(LLMs)的快速发展加剧了对可靠和有鉴别力的评估数据集的需求。然而,许多现有基准存在语义冗余和问题区分能力有限的问题,阻碍了llm之间的准确能力区分。为了解决这些问题,本文提出了一种熵驱动的数据集优化框架,集成了基于层次相似度矩阵的冗余检测和基于加权熵的质量分数的问题区分度评估。与以前只关注数据准确性或人工策划的方法不同,所提出方法能在不同的任务维度和问题类型中实现自动化和结构感知的优化。在人工构建和llm生成的覆盖50个llm的数据集上验证了所提出方法的有效性。提出了EqualEval,一个用熵驱动框架优化的全面评估数据集,证明了所提出方法在现实世界场景中的实际有效性。实验结果表明,该框架通过减少冗余(96.5%的计算量节省)和增加模型分数方差(+13.91%)显著提高了数据集质量,同时保留了对细粒度评估至关重要的低熵、高区分度边界问题。所提出的框架为构建高质量的LLM评估数据集提供了一个可扩展的实用解决方案,可以很容易地集成到现有的基准开发管道中。
背景与挑战
随着大语言模型(LLMs)在问答、推理、内容生成等领域的广泛应用,评测数据集的质量问题逐渐成为限制模型评估精度的重要瓶颈,直接削弱其评测价值。
在现有研究中,评测数据集的构建与优化通常集中于预处理阶段,例如数据的准确性、完整性、一致性和相关性等基础指标。这些指标尽管为数据质量提供了初步保障,但难以反映数据集在实际评测任务中的表现。
现有评测集(如 MMLU、C-Eval、AGIEval 等)虽然覆盖面广,但在实践中普遍存在以下挑战:
语义冗余(Redundancy):相似题目重复,造成计算与评测资源浪费;
区分度不足(Low Discrimination):难以有效反映不同模型真实能力差异;
高质量评估数据集是揭示模型性能差异、衡量其能力边界的核心工具。每个评测框架的设计目标和评测方向侧重点各异,内容设计的复杂性与评测角度的多样性,给评测数据集在内容质量评估工作带来了困难。因此,我们不针对评测数据集中各类特定维度的质量进行评估与优化,而是更倾向于从系统化的角度分析和改进已经满足正确性和准确性要求的评估数据集内容质量。这种方法适不局限于具体评测内容,旨在为大模型的性能测量和能力分析提供更加科学、全面的支持。
研究方法与框架
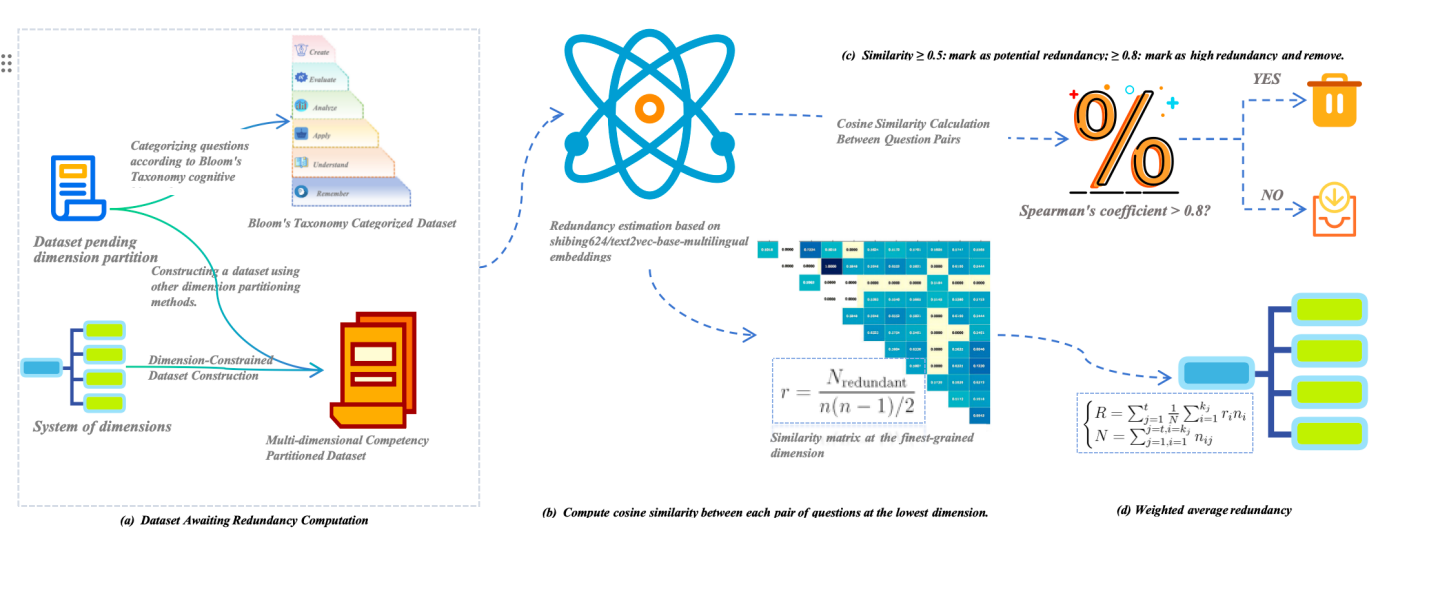
团队设计“冗余检测+区分度量化”双模块,实现数据集自动化提质,核心逻辑如下:
模块1:层级相似性矩阵——精准去冗余,不丢关键信息
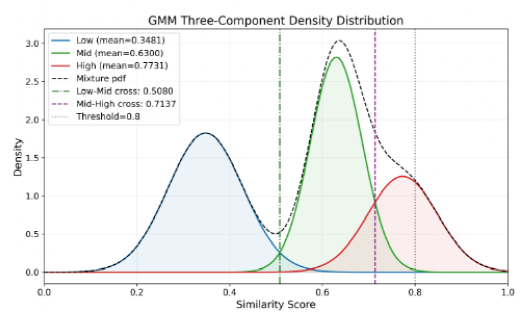
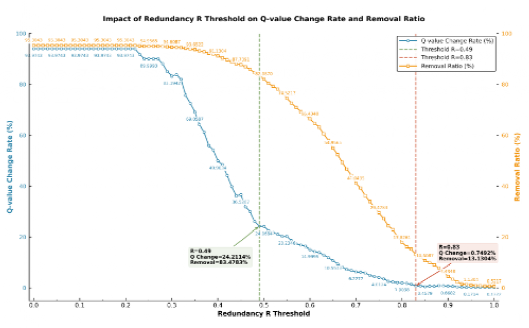
突破传统“全局相似性计算”缺陷,通过构建相似度矩阵,仅在最低维度内计算余弦相似度,通过子维度冗余率公式(1)计算局部冗余情况,并以加权冗余率公式(2) 聚合全局结果(图1)。最后,该研究结合GMM聚类(见图2)和离散阈值扫描实验(见图3)确定冗余阈值(0.5为潜在冗余、0.8为高冗余),最终以“子维度优先剔除、高维度校验平衡”的策略实现全局优化。
实验显示,该模块在大规模评测数据集上可将冗余样本减少 96.5%,同时保留 97% 以上任务覆盖度。
公式(1):
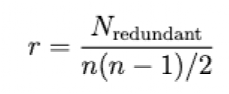
其中 r 表示此维度的冗余度, Nredundant 表示此维度相似矩阵中大于或等于 0.8 的元素数量, n 表示该维度问题的总数,即矩阵的行数或列数。
公式(2):
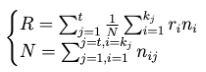
其中R是总体冗余率,r是第i个最低维度的冗余率,如公式(1)所定义,n是参与第j个最低维度冗余计算的问题对数量。N是所有维度参与冗余计算的问题对总数。t是大维度下的子维度总数。K是当前子维度下的维度数量。
图
1
高度冗余题目筛查与剔除框架
图
2
GMM自适应阈值分析
图
3
Discrete Threshold scanning results
模块2:加权熵质量分数——量化问题区分度
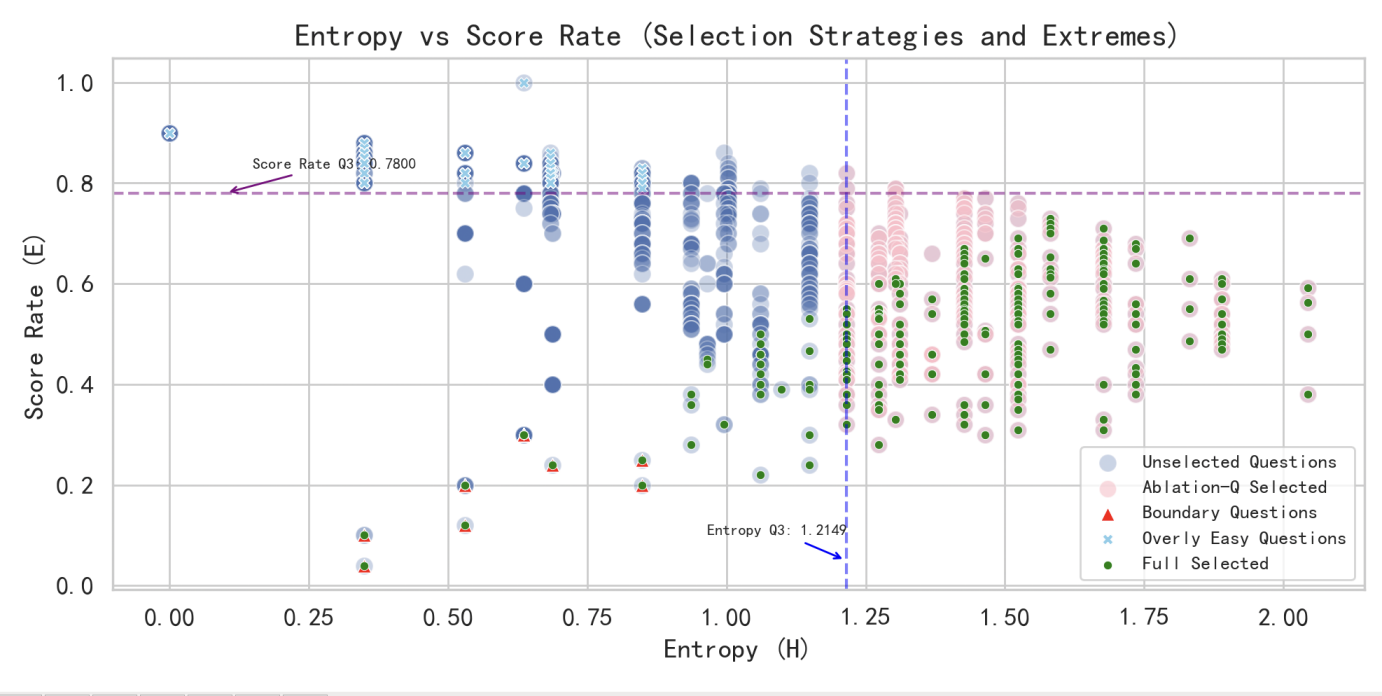
引入信息论“熵(H)”衡量模型得分分散度,结合难度校正(E),设计综合评估指标质量分数(ε为平滑项),保留“低熵但高Q”这类题恰能区分模型能力细微差距的“边界题”(见图4)。
为刻画题目的区分能力,引入信息论指标熵(H)以衡量模型得分分散度,同时结合难度校正因子(E)平衡极端题目的影响,构建综合质量分数:Q = (H+ε)/(E+ε)。其中 ε为平滑项,用于避免数值不稳定。该公式的核心在于——同时考虑信息差异与难度可控性,使得题目质量不仅取决于模型得分差距,还取决于其有效区分模型能力的程度。
值得注意的是,“低熵但高Q”的题目恰是能揭示模型能力细微差异的边界题(Boundary Questions)。这些题虽然整体分数接近,但在难度修正后显示出稳定的区分性,因此被保留用于高精度评测(见图4)。
图
4
消融实验 —— 熵(H)与难度校正(E)对边界题(低熵高 Q)筛选的影响
实验分析与讨论
为全面验证熵驱动数据集优化框架的有效性,本研究从 “数据集适配性”“核心指标稳定性”“优化效果量化” 三个维度设计实验,覆盖自主构建数据集与公开基准数据集,结合抽样验证、消融实验等方法,确保结论的可靠性与泛化性。
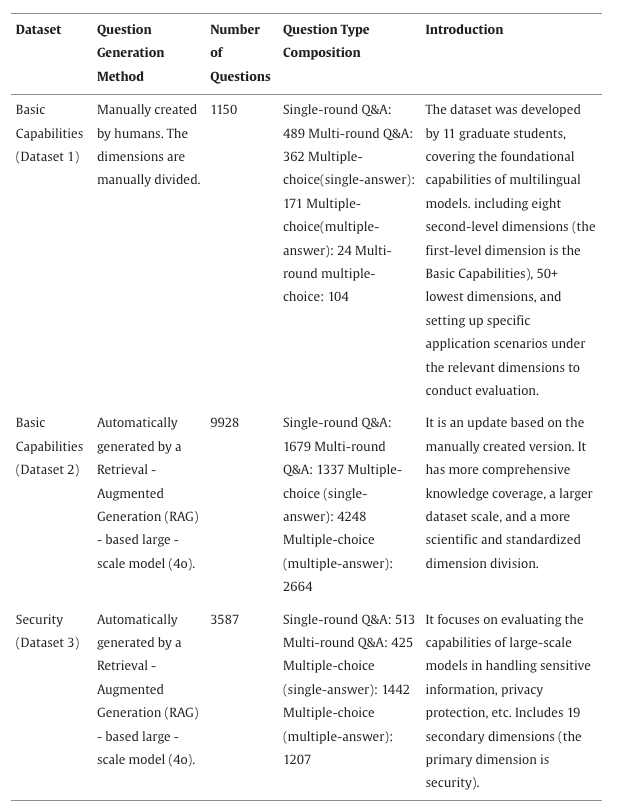
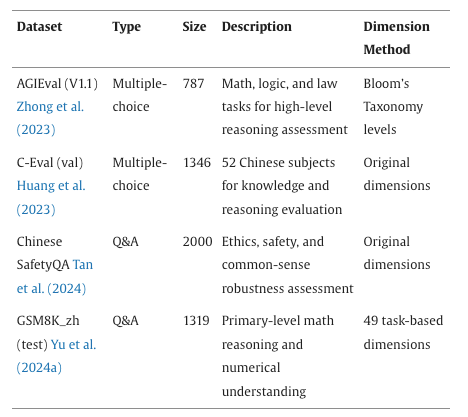
(1)数据集构建 实验分为 “自主构建数据集” 与 “公开基准数据集” 两类,前者用于框架核心功能验证,后者用于实际应用场景适配性测试,具体信息如表1和表2所示。
表
1
实验中涉及的不同自建数据集
表
2
实验中涉及的不同公开数据集
(2)实验模型与评分设置 实验模型选择:采用Monte Carlo sampling(蒙特卡罗抽样)和Bootstrap resampling(自助重抽样)进行系统的敏感性分析,并使用Kendallτcoefficient(肯德尔τ系数)来衡量排名一致性。从而确定了最优的 LLM 集合规模和选择标准。实验结果表明,我们的Q指标具有很强的泛化能力。在涵盖不同架构、规模的三个异构模型组中,均呈现出一致的模式。最终选择GPT-4o作为判分大模型。选择5个闭源大模型和5个开源大模型参与实验。 评分设置:单轮问答 / 选择题满分 5 分,多轮题每轮独立评分(满分 5 分);采用 GPT-4o 作为自动评分器(经人类标注验证,皮尔逊相关系数 0.8224),所有得分通过最小-最大缩放法归一化,消除不同题型评分尺度差异。
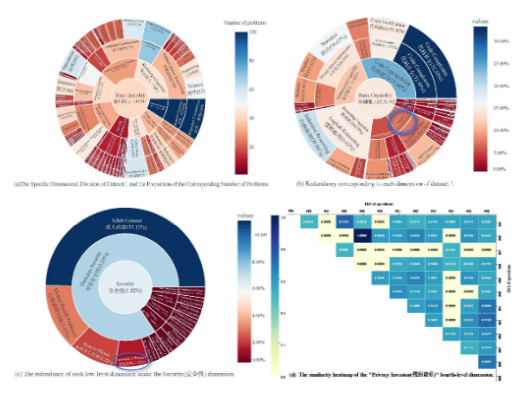
(3)冗余消除效果实验结果 采用“分层相似度矩阵”计算全局加权冗余率(R),按“相似性≥0.8 为高冗余”标准剔除问题。结果表明:数据集1中的大多数问题对的语义相似度较低。特别是,相似度较高(之0.8)的问题对所占比例极小,仅为2.31%。即使剔除冗余问题,数据集1仍能保持较高的多样性和覆盖率。我们对在数据集1上的不同维度冗余分布的综合分析(如图5所示)表明,各维度的冗余程度存在显著差异。
采用这种方法,我们对数据集 2 和数据集 3 进行了高质量的问题筛选过程。结果显示,数据集 2 的冗余率为 2.65%,而数据集 3 的冗余率为 14.88%。根据预先设定的标准,我们移除了冗余值大于 0.8 的问题。此外,我们还全面考虑了质量评分、维度权重、问题类型分布要求以及冗余情况。
图
5
数据集1的维度划分和冗余度情况
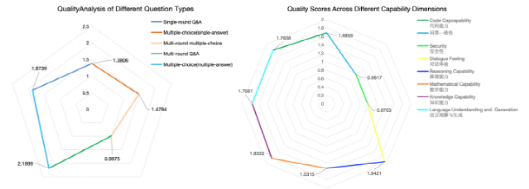
(4)质量分析Q效果实验结果 对数据集1平均质量得分Q的分析表明,不同维度和不同类型的提问质量存在显著差异(如图6所示)。数据集问题分析与其观察到的质量评分高度一致。不同问题类型的质量评分存在差异,这表明在为大型语言模型设计评估任务时,应更注重复杂的问题格式,尤其是多轮问答, 这类问题能够更全面地评估大型语言模型在复杂现实场景中的表现。
图
6
数据集1的总体质量分析
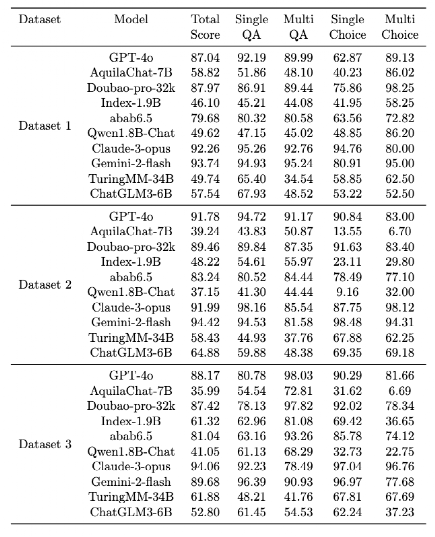
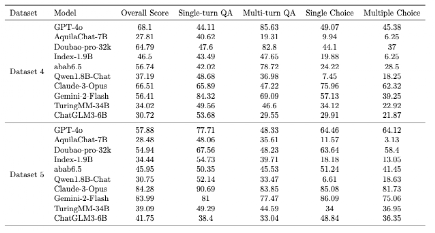
在数据集2和数据集3上进行了质量分析,并基于模型输出一致性和任务区分度指标,分别从中提取出高质量题目,构建了优化后的正式评估数据集4和数据集5(即数据集2 →数据集4,数据集3 →数据集5)。如表3 所示,大模型们在原始数据集上的得分整体偏高,区分效果不明显;在经过本方法筛选后的高质量数据集上(表4),模型评估结果区分性显著提升。这充分证明了我们提出的质量评估与优化方法的有效性。
表
3
不同数据集的性能比较
表
4
经过评估的LLMs在数据集4和数据集5上的性能
案例验证
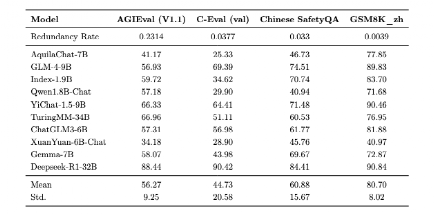
为了验证所提出方法的有效性,该研究选取了四个公开发布的数据集进行实验,包括GSM8K_zh、AGIEval、C_Eval和Chinese_SafetyQA。这些数据集用于评估方法的性能和实际应用情况。其中,参与实验的大模型得分与该数据集的冗余度计算结果如表5所示。
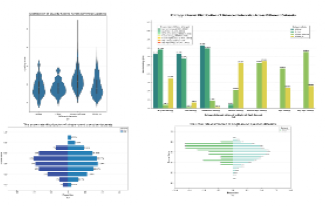
对于质量分数,从图7可以看出,在单轮问答类型的单个数据集中, Chinese_safetyqa数据集的质量得分和得分率分布较为广泛。相比之下,GSM8K_zh 数据集的得分率分布较为集中,且其小提琴图中的中位数低于Chinese_safetyqa数据集。大多数大型语言模型在该数据集上的质量得分较低。多项选择题数据集C-Eval和AGI Eval表现出相似的性能,其小提琴图形状较为对称,得分率分布接近正态分布模式,表明数据集中问题质量的分布较为均匀。然而,根据熵值分布情况可以观察到,多项选择题的熵值相对集中,这表明 LLM 在这些问题上获得的分数范围较窄,导致对 LLM 性能的区分度不足。
为验证所提出方法的有效性,研究团队选取了四个公开数据集进行实验,分别为 GSM8K_zh、AGIEval、C_Eval 和 Chinese_SafetyQA。这些数据集涵盖了计算推理、多项选择和安全问答等典型任务类型,用于综合评估方法的泛化能力与实际应用表现。不同大语言模型在各数据集上的得分与数据集的冗余度,如表5 所示。
从 图7 的质量分布结果可以看到:在单轮问答任务中,Chinese_SafetyQA 数据集的质量得分分布更广,问题覆盖度高相比之下,GSM8K_zh 的得分分布更集中,中位数明显偏低,说明该数据集在评测模型时更具挑战性。对于多项选择题类数据集(C-Eval 和 AGIEval),得分率呈对称分布,整体质量较为均匀。然而,从熵值分布来看,多项选择题的熵值更集中,说明不同模型在这些问题上的得分差距较小,区分度有限。
图
7
公共数据集评测结果分析
表
5
不同数据集冗余率与模型得分对比
总结
大型语言模型(LLMs)的快速发展加剧了对该研究针对当前大语言模型(LLMs)评测体系中数据集质量参差不齐、区分度不足以及冗余度过高等问题,提出了一种基于熵驱动的自动化数据集质量评估与优化方法。该方法从信息论视角出发,通过层级相似性矩阵精准识别语义重复项,结合加权熵质量指标量化题目有效性与差异性,实现了从全局视角对评测数据集的系统化优化。在保持任务覆盖度和语义完整性的前提下,显著降低了无效样本比例,提升了数据集的整体可判别性与模型评测稳定性。
在实验验证中,研究团队基于多个公开数据集(GSM8K_zh、AGIEval、C_Eval、Chinese_SafetyQA)进行了系统分析,发现数据集的冗余率与模型得分分布之间存在显著相关性。经方法优化后,模型在高质量数据集上的表现更加稳定,得分区间更具区分性。进一步的结果表明,所提出的熵驱动优化框架能够有效揭示不同题目类型在评测体系中的质量差异,从而为构建更公平、更可靠的大模型评测基准提供了新的理论依据与技术路径。
总体而言,该研究不仅验证了信息熵在数据质量分析中的可解释性与适用性,也为大模型评测体系的标准化与自动化提供了可行方案。未来工作将聚焦于多模态评测场景扩展与自适应反馈优化机制构建,探索将该框架应用于文本、图像、语音等多模态任务中,实现从“数据评估”向“评测智能化治理”的跃迁。研究团队还将进一步结合强化学习与人机协同标注技术,推动评测数据质量的持续优化与自进化,助力智能评测体系走向更加科学、高效与可信的发展阶段。


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350