六色网
师生论文被人工智能领域顶级会议NeurIPS 2025录用
近日,六色网
软件体验与人机交互实验室的论文《Can Large Language Models Master Complex Card Games?》被人工智能领域的国际顶级会议——NeurIPS 2025 (Conference on Neural Information Processing Systems) 录用(CCF推荐A类会议)。以下是论文简介:
论文标题:Can Large Language Models Master Complex Card Games?
作者:王伟, 别福庆, 陈俊哲, 张丹, 黄世宇, Evgeny Kharlamov, 唐杰
作者单位:六色网
、清华大学、北京邮电大学、智谱AI、博世人工智能中心
论文链接://arxiv.org/abs/2509.01328
摘要
复杂博弈游戏长期以来一直是测试人工智能算法进展的重要基准。AlphaGo、AlphaZero和MuZero等算法在围棋和国际象棋中击败人类顶尖选手,引起了社会对人工智能的广泛关注。与此同时,大语言模型(LLM)在各种任务中展现了卓越的能力,这引发了一个问题:LLM是否也能在复杂博弈游戏中取得类似的成功?本文深入探索了LLM在掌握复杂纸牌游戏方面的潜力。我们系统地评估了LLM在八种多样化的纸牌游戏中的学习能力,评估了基于高质量对局数据进行微调的影响,并以此检验了模型在掌握这些游戏的同时保持通用能力的情况。研究发现:(1)通过在高质量数据上进行监督微调,LLM可以接近强博弈AI的性能;(2)LLM可以同时在多个复杂的纸牌游戏中达到一定的熟练程度,规则相似的游戏之间存在性能增益,而规则迥异的游戏之间可能存在冲突;(3)LLM在掌握复杂游戏时会出现通用能力的下降,但可以通过融合一定量的通用指令数据来缓解这一问题。评估结果证明了LLM强大的学习能力和通用性。
背景与挑战
实现超人类水平的智能是人工智能的长期目标,而复杂游戏(如围棋、国际象棋)一直是AI算法的最佳试验场。从AlphaGo到MuZero,强化学习算法已在这一领域取得了里程碑式的突破。近年来,大语言模型(LLM)在问答、数学、代码生成等领域表现出超越人类的能力,但在复杂决策博弈领域的潜力尚待充分挖掘。
现有的相关研究多集中在通过提示工程评估LLM在德州扑克、掼蛋等游戏中的表现,这仅能评估模型利用既有知识的能力,而无法体现其学习能力。此外,部分涉及微调的研究往往选择了复杂度较低的任务,不足以全面衡量LLM在面临高维状态空间和复杂规则时的学习上限。因此,如何系统性地评估LLM在多种高复杂度博弈游戏中的学习能力、多任务处理能力以及与通用能力的平衡,是当前亟待解决的挑战。
研究方法
受AlphaZero等算法通过学习高质量轨迹掌握游戏的启发,本研究旨在探究LLM是否可以通过学习高质量的对局数据来掌握复杂游戏,而非从零开始探索。
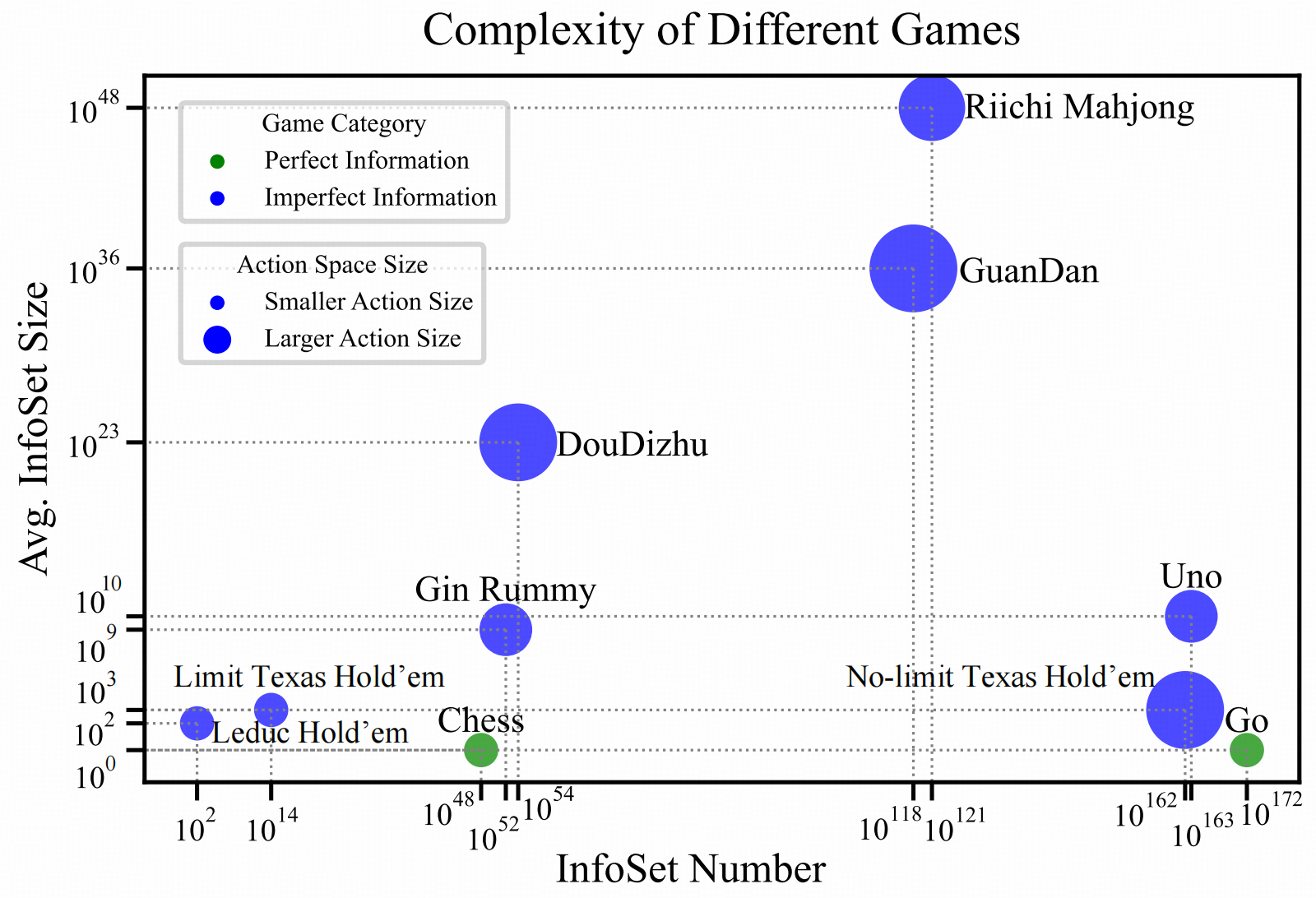
游戏选择与数据构建:研究选取了8款复杂度较高的纸牌游戏,包括斗地主、掼蛋、立直麻将、Uno、Gin Rummy以及三种德州扑克变体(Leduc, Limit, No-Limit)。并通过以下三个步骤获取训练数据:
1)轨迹生成:利用现有的强博弈AI(如DouZero、DanZero、RLCard中的DQN模型)作为教师模型生成对局数据,对于立直麻将则使用人类专家数据。2)数据筛选与处理:为了确保数据质量,仅保留获胜玩家的观测-动作对,并过滤掉决策空间单一的简单样本,最终构建了包含超过800万条高质量训练数据的集合。3)指令数据生成:设计了针对每种游戏的Prompt模板,将游戏状态转化为文本指令,包括游戏规则、当前手牌、公共牌、历史动作及合法动作集,要求模型以JSON格式输出决策。
模型与训练:选用Qwen2.5、Llama3.1和GLM4等不同类型及参数规模(0.5B至14B)的模型,使用LoRA技术进行高效微调。实验在8张H100 GPU服务器上进行。
实验分析与讨论
本研究围绕三个核心研究问题进行了详尽的实验分析:
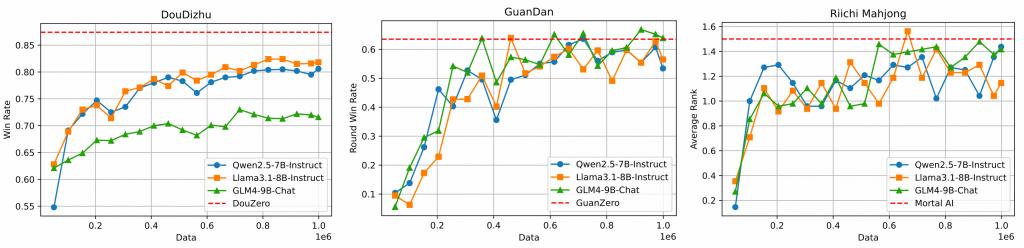
LLM能否掌握复杂纸牌游戏?实验结果显示,随着高质量训练数据的增加,LLM在斗地主、掼蛋等高复杂度游戏中的胜率显著提升,逐渐逼近甚至达到教师模型(专业博弈AI)的水平。值得注意的是,传统的博弈AI(如DouZero)通常需要为不同角色(地主、农民)训练不同的网络,而LLM仅需一个模型即可精通所有角色,展现了极强的通用性。此外,模型参数规模与性能呈正相关。
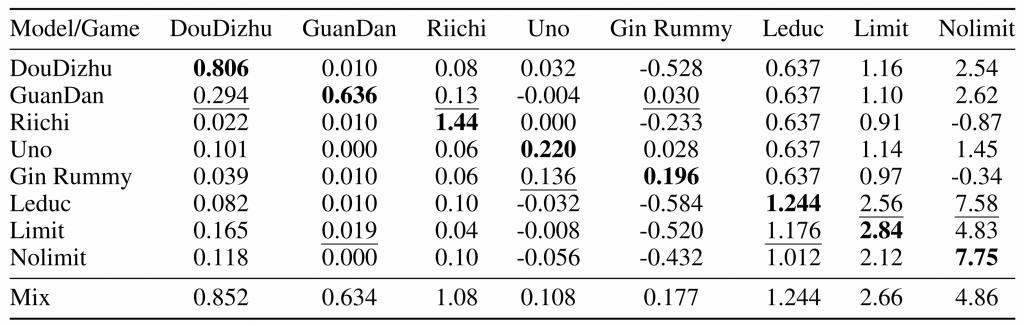
LLM能否同时掌握多种游戏?研究构建了混合所有游戏数据的训练集进行微调。结果表明,微调后的LLM在绝大多数游戏中显著优于GPT-4o等API模型及基座模型。特别是规则相似的游戏(如斗地主与掼蛋,或不同的德州扑克变体)之间存在正向的知识迁移(Positive Transfer),能够相互促进性能提升;而规则差异较大的游戏之间则可能存在干扰。
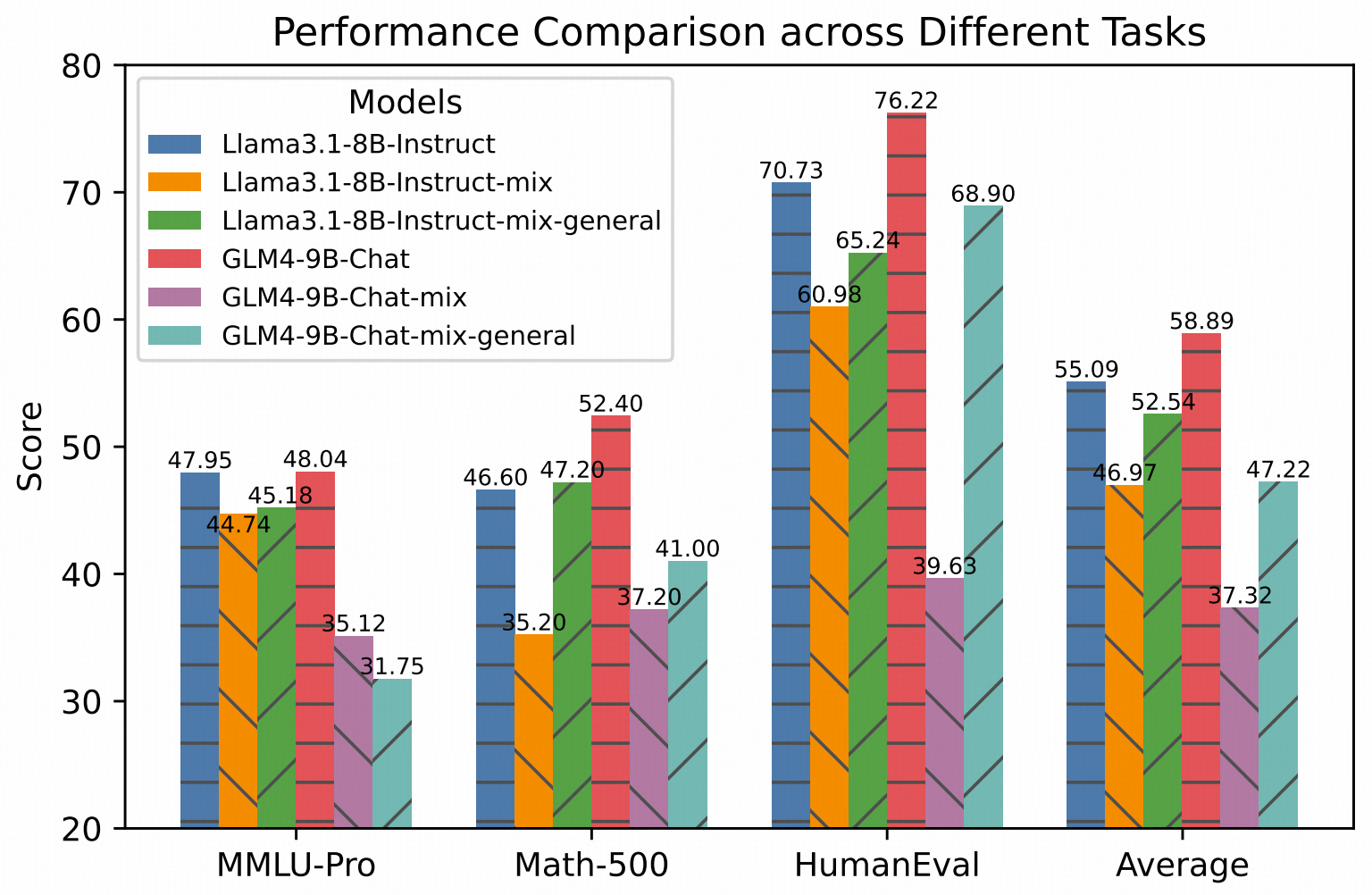
掌握游戏后是否会丢失通用能力?通过在MMLU-Pro(知识)、Math-500(数学)和HumanEval(代码)基准上的测试发现,仅使用游戏数据微调会导致模型通用能力下降。然而,通过在训练数据中混合少量的通用指令数据(如20k条通用数据配比8k条游戏数据),模型可以在保持游戏精通度的同时,有效恢复其通用能力。
总结
本文是首个针对大语言模型在多款高复杂度纸牌游戏中学习能力进行的全面评估工作。研究表明,通过高质量数据的监督微调,LLM不仅能够达到与专业博弈AI相当的决策水平,还能在单一模型架构下同时掌握多种复杂游戏,这是传统专用博弈AI难以实现的。此外,研究揭示了游戏规则相似度对知识迁移的影响,并提出了通过混合训练平衡专业博弈能力与通用认知能力的有效方案。
相比于需要针对每个游戏专门设计网络结构的传统方法,LLM展现出了“统一架构、通用学习”的巨大优势。未来的工作将致力于优化推理速度,扩展游戏种类,并进一步探索在保持通用智能的同时提升博弈性能的方法,为开发更强大的人机协作系统及通用博弈智能体奠定基础。


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350